This is a small update (1 year later) of a great article by Ilmari Kontulainen, first posted on blog.deveo.com.
I’ll post the original article in blockquote and my notes in green.
Storing large binary files in Git repositories seems to be a bottleneck for many Git users. Because of the decentralized nature of Git, which means every developer has the full change history on his or her computer, changes in large binary files cause Git repositories to grow by the size of the file in question every time the file is changed and the change is committed. The growth directly affects the amount of data end users need to retrieve when they need to clone the repository. Storing a snapshot of a virtual machine image, changing its state and storing the new state to a Git repository would grow the repository size approximately with the size of the respective snapshots. If this is day-to-day operation in your team, it might be that you are already feeling the pain from overly swollen Git repositories.
Luckily there are multiple 3rd party implementations that will try to solve the problem, many of them using similar paradigm as a solution. In this blog post I will go through seven alternative approaches for handling large binary files in Git repositories with respective their pros and cons. I will conclude the post with some personal thoughts on choosing appropriate solution.
git-annex
git-annex allows managing files with git, without checking the file contents into git. While that may seem paradoxical, it is useful when dealing with files larger than git can currently easily handle, whether due to limitations in memory, time, or disk space.
Git-annex works by storing the contents of files being tracked by it to separate location. What is stored into the repository, is a symlink to the to the key under the separate location. In order to share the large binary files between a team for example the tracked files need to be stored to a different backend. At the time of writing (23rd of July 2015): S3 (Amazon S3, and other compatible services), Amazon Glacier, bup, ddar, gcrypt, directory, rsync, webdav, tahoe, web, bittorrent, xmpp backends were available. Ability to store contents in a remote of your own devising via hooks is also supported.
You can see the complete list with links to all the backends at this page
Git-annex uses separate commands for checking out and committing files, which makes its learning curve bit steeper than other alternatives that rely on filters. Git-annex has been written in haskell, and the majority of it is licensed under the GPL, version 3 or higher. Because git-annex uses symlinks, Windows users are forced to use a special direct mode that makes usage more unintuitive.
Latest version of git-annex at the time of writing is 5.20150710, released on 10th of July 2015, and the earliest article I found from their website was dated 2010. Both facts would state that the project is quite mature.
Pros:
- Supports multiple remotes that you can store the binaries. See here
- Can be used without support from hosting provider. See here.
- Supported by Gitlab .
- Support for windows now available for git-annex .
Cons:
Windows support in beta. See here.
- Users need to learn separate commands for day-to-day work
.
Project home page: https://git-annex.branchable.com/
Git Large File Storage (Git LFS)
Git Large File Storage (LFS) replaces large files such as audio samples, videos, datasets, and graphics with text pointers inside Git
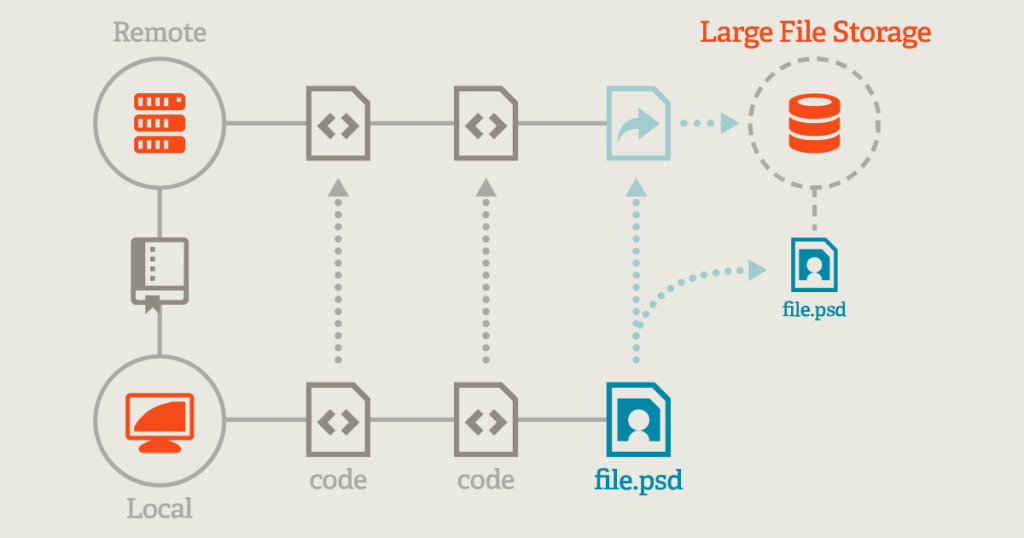
The core Git LFS idea is that instead of writing large blobs to a Git repository, only a pointer file is written. The blobs are written to a separate server using the Git LFS HTTP API. The API endpoint can be configured based on the remote which allows multiple Git LFS servers to be used. Git LFS requires a specific server implementation to communicate with. An open source reference server implementation as well as at least another server implementation is available. The storage can be offloaded by the Git LFS server to cloud services such as S3 or pretty much anything else if you implement the server yourself.
Git LFS uses filter based approach meaning that you only need to specify the tracked files with one command, and it handles rest of it invisibly. Good side about this approach is the ease of use, however there is currently a performance penalty because of how Git works internally. Git LFS is licensed under MIT license and is written in Go and the binaries are available for Mac, FreeBSD, Linux, Windows. The version of Git LFS is 0.5.2 at the time of writing, which suggests it’s still in quite early shape, however at the time of writing there were 36 contributors to the project. However as the version number is still below 1, changes to APIs for example can be expected.
Pros:
- Github behind it.
- Supported by Gitlab .
- Ready binaries available to multiple operating systems.
- Easy to use.
- Transparent usage.
Cons:
- Requires a custom server implementation to work.
-
API not stable yet.
- Performance penalty. This should be handled with the new (Ver 1.2) git lfs clone command, see issue https://github.com/github/git-lfs/issues/931
Project home page: https://git-lfs.github.com/
git-bigfiles – Git for big files
The goals of git-bigfiles are pretty noble, making life bearable for people using Git on projects hosting very large files and merging back as many changes as possible into upstream Git once they’re of acceptable quality. Git-bigfiles is a fork of Git, however the project seems to be dead for some time. Git-bigfiles is is developed using the same technology stack as Git and is licensed with GNU General Public License version 2 (some parts of it are under different licenses, compatible with the GPLv2).
Pros:
- If the changes would be backported, they would be supported by native Git operations.
Cons:
- Project is dead.
- Fork of Git which might make it non-compatible.
- Allows configuring threshold of file size only when tracking what is considered a large file.
Project home page: http://caca.zoy.org/wiki/git-bigfiles
git-fat
git-fat works in similar manner as git lfs. Large files can be tracked using filters in
.gitattributesfile. The large files are stored to any remote that can be connected through rsync. Git-fat is licensed under BSD 2 license. Git-fat is developed in Python which creates more dependencies for Windows users to install. However the installation itself is straightforward with pip. At the time of writing git-fat has 13 contributors and latest commit was made on 25th of March 2015.
Pros:
- Transparent usage.
Cons:
- Project seem dead
- Supports only rsync as backend.
Project home page: https://github.com/jedbrown/git-fat
git-media
Licensed under MIT license and supporting similar workflow as the above mentioned alternatives git lfs and git-fat, git media is probably the oldest of the solutions available. Git-media uses the similar filter approach and it supports Amazon’s S3, local filesystem path, SCP, atmos and WebDAV as backend for storing large files. Git-media is written in Ruby which makes installation on Windows not so straightforward. The project has 9 contributors in GitHub, but latest activity was nearly a year ago at the time of writing.
There seem to be some low activity on this project, latest commit is now on Sep 27, 2015
Pros:
- Supports multiple backends
- Transparent usage
Cons:
-
No longer developed.Low activity on the project
- Ambiguous commands (e.g. git update-index –really refresh).
- Not fully Windows compatible.
Project home page: https://github.com/alebedev/git-media
git-bigstore
Git-bigstore was initially implemented as an alternative to git-media. It works similarly as the others above by storing a filter property to .gitattributes for certain type of files. It supports Amazon S3, Google Cloud Storage, or Rackspace Cloud account as backends for storing binary files. git-bigstore claims to improve the stability when collaborating between multiple people. Git-bigstore is licensed under Apache 2.0 license. As git-bigstore does not use symlinks, it should be more compatible with Windows. Git-bigstore is written in Python and requires Python 2.7+ which means Windows users might need an extra step during installation. Latest commit to the project’s GitHub repository at the time of writing was made on April 20th, 2015 and there is one contributor in the project.
Last commit on June 2016, and there are now 3 contributors.
Pros:
- Requires only Python 2.7+
- Transparent
Cons:
- Only cloud based storages supported at the moment.
Project home page: https://github.com/lionheart/git-bigstore
git-sym
Git-sym is the newest player in the field, offering an alternative to how large files are stored and linked in git-lfs, git-annex, git-fat and git-media. Instead of calculating the checksums of the tracked large files, git-sym relies on URIs. As opposed to its rivals that store also the checksum, git-sym only stores the symlinks in the git repository. The benefits of git-sym are thus performance as well as ability to symlink whole directories. Because of its nature, the main downfall is that it does not guarantee data integrity. Git-sym is used using separate commands. Git-sym also requires Ruby which makes it more tedious to install on Windows. The project has one contributor according to its project home page.
Last commit on Jun 20, 2015, the project seem dead now
Pros:
- Performance compared to solutions based on filters.
- Support for multiple backends.
Cons:
- Does not guarantee data integrity.
- Project seem dead, no commits in 1 year
- Does not guarantee data integrity.
Project home page: https://github.com/cdunn2001/git-sym
Conclusion
There are multiple ways to handle large files in Git repositories and many of them use nearly similar workflows and ways to handle the files. Some of the solutions listed are no longer developed actively, thus if I were to choose a solution currently, I would go with git-annex as it has the largest community and support for various backends. If Windows support or transparency is a must-have requirement and you are okay living with the performance penalty, I would go with Git LFS, as it will likely have long term support because of its connections with GitHub.
How have you solved the problem of storing large files in git repositories? Which of the aforementioned solutions have you used in production?
Useful links
If You’re Not Using Git LFS, You’re Already Behind!
Git Annex vs. Git LFS
Git LFS 1.2: Clone Faster
Popular Posts:
- None Found
![]()