Today I want to repost for my readers a really interesting article by Gionatan Danti first posted on his blog http://www.ilsistemista.net/, I hope you enjoy it as much as I do
File compression is an old trick: one of the first (if not the first) program capable of compressing files was “SQ”, in the early 1980s, but the first widespread, mass-know compressor probably was ZIP (released in 1989).
In other word, compressing a file to save space is nothing new and, while current TB-sized, low costs disks provide plenty of space, sometime compression is desirable because it not only reduces the space needed to store data, but it can even increase I/O performance due to the lower amount of bits to be written or read to/from the storage subsystem. This is especially true when comparing the ever-increasing CPU speed to the more-or-less stagnant mechanical disk performance (SSDs are another matter, of course).
While compression algorithms and programs varies, basically we can distinguish to main categories: generic lossless compressors and specialized, lossy compressors.
If the last categories include compressors with quite spectacular compression factor, they can typically be used only when you want to preserve the general information as a whole, and you are not interested in a true bit-wise precise representation of the original data. In other word, you can use a lossy compressor for storing an high-resolution photo or a song, but not for storing a compressed executable on your disk (executable need to be perfectly stored, bit per bit) or text log files (we don’t want to lose information on text files, right?).
So, for the general use case, lossless compressors are the way to go. But what compressor to use from the many available? Sometime different programs use the same underlying algorithm or even the same library implementation, so using one or another is a relatively low-important choice. However, when comparing compressors using different compression algorithms, the choice must be a weighted one: you want to privilege high compression ratio or speed? In other word, you need a fast and low-compression algorithm or a slow but more effective one?
In this article, we are going to examine many different compressors based on few different compressing libraries:
- lz4, a new, high speed compression program and algorithm
- lzop, based on the fast lzo library, implementing the LZO algorithm
- gzip and pigz (multithreaded gzip), based on the zip library which implements the ZIP alg
- bzip2 and pbzip2 (multithreaded bzip2), based on the libbzip2 library implementing the Burrows–Wheeler compressing scheme
- 7-zip, based mainly (but not only) on the LZMA algorithm
- xz, another LZMA-based program
Programs, implementations, libraries and algorithms
Before moving to the raw number, lets first clarify the terminology.
A lossless compression algorithms is a mathematical algorithms that define how to reduce (compress) a specific dataset in a smaller one, without losing information. In other word, it involves encoding information using fewer bit that the original version, with no information loss. To be useful, a compression algorithms must be reversible – it should enable us to re-expand the compressed dataset, obtaining an exact copy of the original source. It’s easy to see how the fundamental capabilities (compression and ratio and speed) are rooted in the algorithm itself, and different algorithms can strongly differ in results and applicable scopes.
The next step is the algorithm implementation – in short, the real code used to express the mathematical behavior of the compression alg. This is another critical step: for example, vectorized or multithreaded code is way faster than plain, single-threaded code.
When a code implementation is considered good enough, often it is packetized in a standalone manner, creating a compression library. The advantage to spin-off the alg implementation in a standalone library is that you can write many different compressing programs without reimplement the basic alg multiple times.
Finally, we have the compression program itself. It is the part that, providing a CLI or a GUI, “glues” together the user and the compression library.
Sometime the alg, library and program have the same name (eg: zip). Other times, we don’t have a standalone library, but it is built right inside the compression program. While this is slightly confusing, what written above still apply.
To summarize, our benchmarks will cover the alg, libraries and programs illustrated below:
| Program | Library | ALG | Comp. Ratio | Comp. Speed | Decomp. Speed |
| Lz4, version r110 | buit-in | Lz4 (a LZ77 variant) | Low | Very High | Very High |
| Lzop, version 1.02rc1 | Lzo, version 2.03 | Lzo (a LZ77 variant) | Low | Very High | Very High |
| Gzip, version 1.3.12 | built-in | LZ77 | Medium | Medium | High |
| Pigz, version 2.2.5 | Zlib, version 1.2.3 | LZ77 | Medium | High (multithread) | High |
| Bzip2, version 1.0.5 | Libbz2, 1.0.5 | Burrows–Wheeler | High | Low | Low |
| Pbzip2, version 1.1.6 | Libbz2, 1.0.5 | Burrows–Wheeler | High | Medium (multithread) | Medium (multithread) |
| 7-zip | built-in | LZMA | Very High | Very Low (multithread) | Medium |
| Xz,version 4.999.9 beta | Liblzma, ver 4.999.9beta | LZMA | Very High | Very Low | Medium |
| Pxz,version 4.999.9 beta | Liblzma, ver 4.999.9beta | LZMA | Very High | Medium (multithread) | Medium |
Testbed and methods
Benchmarks were performed on a system equipped with:
- PhenomII 940 CPU (4 cores @ 3.0 GHz, 1.8 GHz Northbridge and 6 MB L3 cache)
- 8 GB DDR2-800 DRAM (in unganged mode)
- Asus M4A78 Pro motherboard (AMD 780G + SB700 chipset)
- 4x 500 GB hard disks (1x WD Green, 3x Seagate Barracuda) in AHCI mode, configured in software RAID10 “near” layout
- S.O. CentOS 6.5 x64
I timed the compression and decompression of two different datasets:
- a tar file containing an uncompressed CentOS 6.5 minimal install / (root) image (/boot was excluded)
- the tar file containing Linux 3.14.1 stable kernel
In order to avoid any influence by the disk subsystem, I moved both dataset in the RAM-backed /dev/shm directory (you can think about it as a RAMDISK).
When possible, I tried to separate single-threaded results from multi-threaded ones. However, it appear that 7-zip has no thread-selection options, and by default it spawn as many threads as the hardware threads the CPU provide. So I marked 7-zip results with an asterisk (*)
Many compressors expose some tuning – for example, selecting “-1” generally means a faster (but less effective) compression that “-9”. I experimented with these flags also, where applicable.
Compressing a CentOS 6.5 root image file
Let start our analysis compressing a mostly executables-rich dataset: a minimal CentOS 6.5 root image. Executables and binary files can often be reduced – albeit with somewhat low compression ratios.
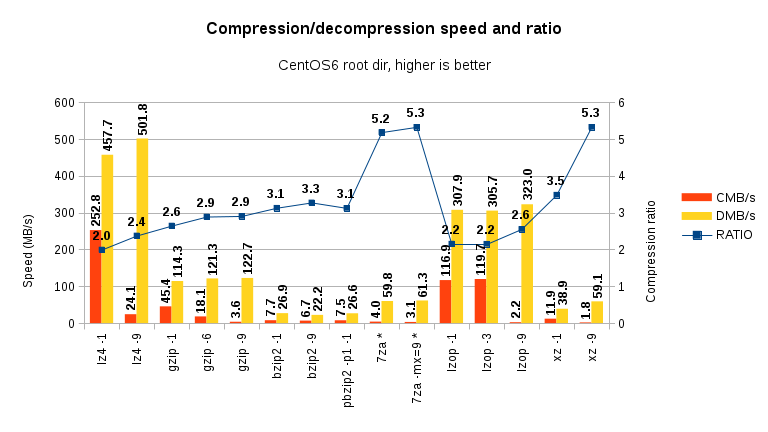
As you can see, both lz4 and lzop maintain their promise to be very fast, both at compression and decompression – albeit lz4 is the absolute winner. On the other hand, they have relatively low compression factor. However, ask them to increase their compression ratio (via “-9” switch) and they slow down immensely, without producing appreciably smaller files.
Gzip and especially bzip2 shows are not so good – while their compression factor is better (3X), they suffer a massive performance hit.
7-zip and xz have very low compression speed, but very high compression ratio and acceptable decompression speed.
Remember that these are single-threaded results. Moder CPU, with multiple cores, can be put to good use using some multi-threaded compression programs:
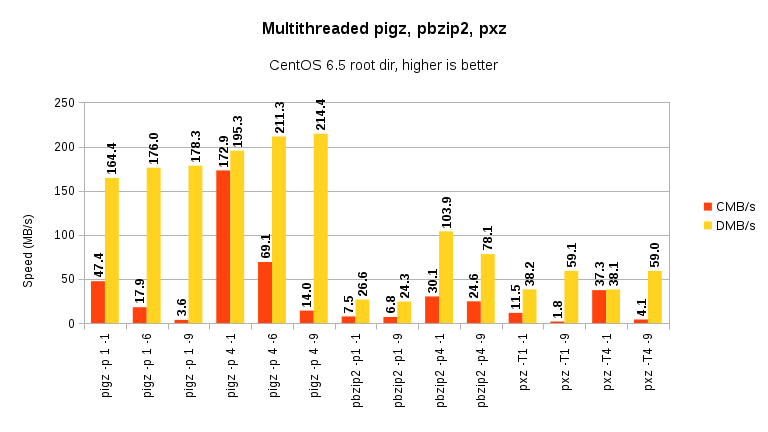
Scaling:

Pigz, pbzip2 and pxz all produce way better results than theri single-threaded counterparts. However, while compression scaling is often very good, only pbzip2 is capable of decompression acceleration also.
Compressing the linux kernel 3.14.1 sources
Sources are text files, and text files generally have very good compression ratios. Let see how our contenders fare in compressing the linux kernel 3.14.1 source tar file:

While the relative standing remains the same, we can see two differences:
- as expected, the compression ratio is somewhat higher
- lzop is considerably faster at compression compared to the previous run.
Now, the multi-threaded part:

and scaling:
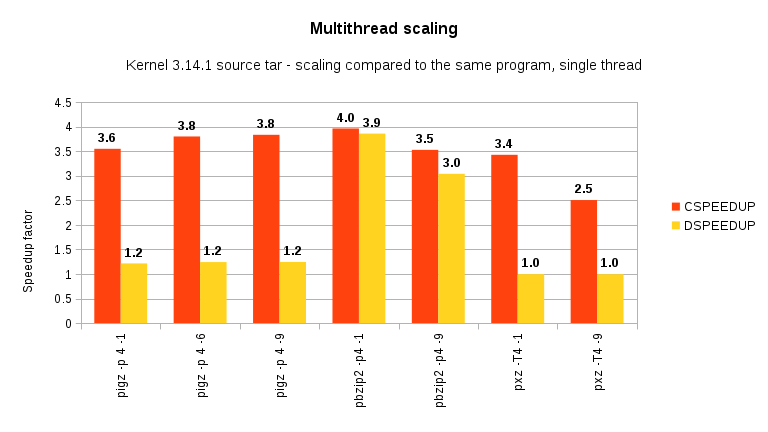
Compression scaling remain excellent, with pxz in the last place.
Conclusions
From the above benchmarks, is clear that each contender has it specific use case:
- lz4 and lzop are very good for realtime or near-realtime compression, providing significant space saving at a very high speed
- gzip, especially in the multithreaded pgiz version, is very good at the general use case: it has both quite good compression ratio and speed
- vanilla, single-threaded bzip2 does not fare very well: both its compression factor and speed are lower than xz. Only the excellent pbzip2 multithreaded implementation somewhat redeem it
- xz is the clear winner in the compression ratio, but it is one of the slower programs both at compressing and decompressiong. If your main concern is compression ratio rather than speed (eg: on-line archive download) you can not go wrong with it
- 7zip basically is a close relative of xz, but it main implementation belong to the windows ecosystem. Under Linux, simply use xz instead of 7-zip.
Feel free to discuss this article with me writing at [email protected]
Popular Posts:
- None Found
![]()
Very useful information.
Also, Rar is a file archiver with a very high compression ratio. It would be really interesting to see what are the advantages of Rar and how it performs against other compressors in a Linux environment, especially on a Linux VPS.